Introduction
Protocols WS-Trust, WF-Federation, and SAML are mainly used for connecting federated businesses in a secure manner. To be implemented, these protocols mandates certain infrastructure in order to operate: public key inftrastrucutre (PKI), security policies, and predefined security boundaries and setup are examples.
In the web space such constraints can be limiting as the main promise of the web is flexibility and loose coupling between clients (users) and the services they use (for example social media services such as facebook or twitter).
The most popular protocols in the web space are OpenId and OAuth. OpenId is the topic of this article, OAuth in the next.
OpenID 2.0
The promise of OpenID is basically the same as that of protocols WF-Federation and SAML: it allows services to delegate identity management and authentication to other services.
Users create accounts with OpenID providers (such as Google and Yahoo!). Whenever they want to login in to an OpenID consumer site (relying party in the previous terminology), they do so using an OpenID identity generated by the provider. This way, users create a single account (OpenID identity) and use it to log in to multiple services that accept this identity.
OpenID facilitates SSO between different relying parties once you sign in to a certain OP. For example, if you login to Yahoo using Google identifier (Yahoo is also a relying party for Google users), then you get SSO if you try to login to Stackoverflow also using Google.
The OpenID protocol defines the communication between the OpenID provider and the OpenID consumer service (i.e. the relying party).
Protocol Overview
Step1: Users Initiates Authentication Request
An end user wants to access a Relying Party that accepts OpenID assertions. The user’s browser sends a User-Supplied Identifier to the Relying Party.
The User-Supplied identifier can be either:
· A Claimed Identifier which is under the control of a user as a result of delegation. For example
www.mysite.com (see about delegation at the end of this section)
Claimed Identifier is sometimes used interchangeably with OP-Local Identifier, although the separation is required in case of delegation as explained above.
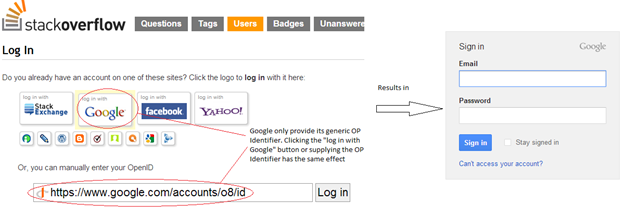
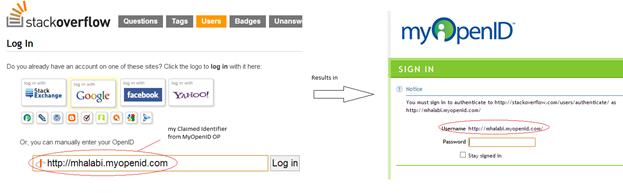
To clarify this, Google for example – as far as I know – does not give its users a fixed Claimed Identifier to use. Instead users supply a generic OP Identifier which then guides users into selecting their specific identifiers. You see this in effect when you see the button “Sign In using Google” in Relying Parties sites. MyOpenID on another hand gives its users their specific Claimed Identifiers to log in to relying parties (the “Sign In using Yahoo” button might also be used).
So to sum up this step, if an OP Identifier is used, users click the “Sign In with ProviderX” button. If users have their own Claimed Identifier then users might type it into an input field.
The below screen shots shows the two ways using Stackoverflow as a relying party.
Delegation:
Say you own a domain name and you want it to be your identifier. OpenID allows you to use your own domain name as your identifier. For example let’s say you own domain
www.mysite.comand want to use this URL as your identifier instead of mhalabi.myopenid.com. To achieve this, just add the following markup into the header section of
www.mysite.com:
Now you can use
www.mysite.comto log in to relying parties with MyOpenID as the OP which will however verify mhalabi.myopenid.com.
The obvious advantage about delegation is that should we want to change the OP, we can do so with still relying on the identifier of our choice. We just have to change the hrefs of the above markup.
Step2: Discovery
The relying party uses the identifier supplied and performs discovery to know the OpenID Provider Endpoint URL. This is an absolute Http or Https URL that accepts authentication messages.
As you can see, discovery here is in contrast to the trust model adopted in protocols such as WS-Federation and SAML where relying parties and providers must go into a pre-agreement which makes these protocols more suitable to business-to-business federation of identities. The discovery model of OpenID makes it more appropriate to the web space where service endpoints change rapidly and users consume services in a loose manner.
Discovery can happen in three ways:
· If the identifier is an XRI, XRI Resolution will yield an XRDS document that contains the necessary information.
· If it is a URL, the Yadis protocol shall be first attempted. If it succeeds, the result is again an XRDS document.
· If the Yadis protocol fails and no valid XRDS document is retrieved, or no Service Elements are found in the XRDS document, the URL is retrieved and HTML-Based discovery SHALL be attempted.
XRI
Extensible Resource Identifier (XRI) is a scheme and resolution protocol that works for identifiers independent of domain, location, application, and transport. XRI resolution yields an Extensible Resource Descriptor Sequence (XRDS) document which contains the location of the OpenID Provider service.
So why XRI?
As discussed in delegation, you can use your own URL as your identifier to login to websites. Relying parties in turn usually store users identifiers along with user profile information. However, domain names can be lost and acquired by other people (for example in case of expiration or not renewing).
Whenever you lose the domain, you lose your identifier as well. Whoever now owns the domain can delegate authentication to a provider where he/she can authenticate. Now when redirected back to a relying party which previously stored the domain name identifier (when you owned it), the new domain owner will access your account.
XRI prevents this from happening by giving users automatically generated unique i-numbers as their identifiers. These will never be reassigned. Relying parties store this i-number to uniquely identify users.
XRI defines two identifier: i-names and i-numbers where i-names are human readable while i-numbers are machine readable.
Yadis
Yadis is a service discovery protocol. Discussing the full specification is out of scope but you can have a look here (link). What concerns me here is how Yadis is used in OpenID discovery context.
OP must publish their service information using a XRDS document. Yadis protocol is used as the method of discovery when the user supplies an URL as an identifier (as opposed to XRI – although XRI discovery also results in a XRDS document). The result of Yadis discovery is the XRDS file.
XRDS
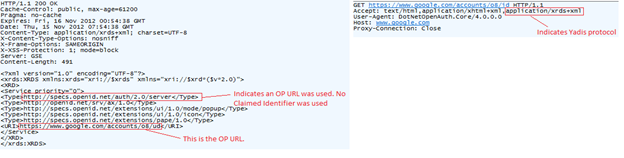
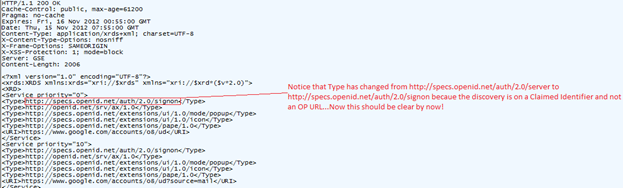
If XRI of Yadis discovery is used, the result will be an Extensible Resource Descriptor Sequence (XRDS) XML document. This document contains entries for service endpoints offered by the provider. The following is an example XRDS document as a result of OpenID discovery:
Type “http://specs.openid.net/auth/2.0/signon” means an Claimed Identifier was supplied by the user, in this case the LocalID is the Claimed Identifier while the URI is the OP endpoint URL.
If Type was set to “http://specs.openid.net/auth/2.0/server” then this means an OP Identifier was supplied by the user, in this no LocalID would be present while again URI would be the OP URL endpoint.
HTML-Based Discovery
So both URL and XRI based discoveries result in XRDS, but what about the third type: HTML-Based Discovery?
HTML-based discovery can be used in case of delegation. Recall that when using delegation, the following HTML markup must be present at the domain URL you claim you own (Claimed Identifier):
Step3: Establishing Association
This is an optional – albeit important step. The relying party and the provider establish a shared secret that is then used by the provider to sign messages and by the relying party to verify those messages. This improves performance as it removes the need for dedicated direct requests to verify the signature after each authentication request/response.
When association is established both the OP and the Relying Party refer to the association key in the name of “assoc_handle”.
If an association is not used, verification is done in a stateless fashion via dedicated verification requests. In this case the OP creates a private association for signing the response. The OP stores this association and the relying party sends direct verification requests to verify the signature.
What are the reasons that would prevent using an association? Well for one, the relying party might not be capable of generating or storing associations. Or maybe the provider is behind a load balancer so in-memory storage of the association is out of question; although this is highly unlikely to be a cause as an association can easily be cached or even stored in a durable storage medium…
Step4: Authentication Request
The relying party now redirects the end user’s browser to the provider with an OpenID Authentication request. The target is to obtain an assertion. You can find a full description of the request parameters in the spec document, but here are some highlights:
· openid.mode: set to either:
o checkid_setup: the end user will interact with the relying party
o checkid_immediate: end user will not interact with the relying party, mostly in scenarios where authentication requests are send using Ajax
· openid.claimed_id: as discussed before, this can be either:
· openid.assoc_handle: as discussed before, the handle of the association if association is used. If missing, then the mode will be stateless.
· Openid.realm: if openid.mode is set to checkid_setup, OP can ask the end user to trust the URL sent in the realm. This results in a page basically asking the user “relying party X is asking info or login from provider Y, do you trust this relying party?” If the user answers “yes” then this means he/she approves the authentication request and the process can carry on, else the user does not approve the request and the relying party’s request for authentication is rejected.
Step5: Perform Authentication
The OP asks the user to authenticate. How this happens is totally independent of the protocol itself. Although the dominant form in the web space is to ask the user to supply a username/password combination, this is not a rule and the OP might authenticate the user in anyway it wants. The response sent back from the OP to the relying party is where the protocol picks up again.
I will just highlight two points here:
- 1- If opened.claimed_id in the authentication request was set to http://specs.openid.net/auth/2.0/identifier_selectthen the user will be prompted by the OP to select the identifier with which he/she would want to authenticate. Else if it was set to a URL claimed by the user (i.e. delegation) or an OP Local Identifier, then the user has already presented his/her identifier and what remains is to authenticate usually by supplying a password associated with this identifier.
- 2 If realm is used, then the user will be asked to verify that he/she approves the authentication by the relying party, as discussed above…
Step6: Send Response
The OP redirects the browser back to the Relying Party with either a positive assertion (i.e. authentication approved) or a negative one. The assertion response is detailed in the specification, but again I want to highlight the following parameters:
· openid.assoc_handle: the handle used for signing the response. This is either the handle for the shared key if association was stabled. Else it will be the handle of the private key generated by the OP.
· openid.signed: the list of the fields that are included in the signature.
· openid.sig: the signature itself
Step7: Verification of Positive Assertions
The Relying Party verifies that the information in the assertion matches the information obtained back in the discovery step.
If the supplied identifier back in the beginning of the process was an OP URL (so the user was prompted to select an identifier), then the Relying Party performs another discovery on the Claimed Identifier in the assertion response to make sure that the OP is authorized to make assertions about this Claimed Identifier.
The Relying Party also verifies the signature by using either the shared key established during the association or by sending a direct request to the OP (as discussed before).
Protocol Extension: Attribute Exchange
The OpenID Attribute Exchange is a protocol extension that allows the transfer if user attributes – such as name, gender, email – from the OP to the Relying Party based on a query from the Relying Party. Each OP might support a different set of attributes; Google for example supports email, name, and country.
When you go through the next section, you will see that the protocol in action when Google sends the user email back to the Relying Party.
.NET Implementation using VS 2012
The most popular way to make your ASP.NET sites OpenID reliant is DotNetOpenAuth. VS 2012 includes DotNetOpenAuth as part of the default ASP.NET templates.
Creating a new ASP.NET in VS 2012 web application will reveal the DotNetOpenAuth libraries:
Locate file AuthConfig.cs inside the App_Start folder and you can see that placeholders are already in place to enable your site for both OpenID and OAuth.
For this example, uncomment line “OpenAuth.AuthenticationClients.AddGoogle();”. This will add Google as an OP for your site, where the site is a Relying Party.
Run the application and click the Login button. You will see that Google has been added as an option to login. Go through the process of logging in and you will be able to map every step discussed when I explained the protocol to what actually goes on.
Let’s quickly walk together some important steps by examining the web traffic through Fiddler.
Once you click the Google button, it means that you have supplied an identifier of value
https://www.google.com/accounts/o8/idwhich is Google OP URL. If this is not clear for you then you should review again the discussion of the protocol to understand the difference between OP URL, Claimed Identifier and OP Local Identifier.
Next, because the identifier supplied is a URL, Yadis discovery starts and the web application (Relying Party) gets back an XRDS document. Below you see the request and the response:
Next you will be prompted to login to Google. Translating this back to the protocol means that you are being asked to select the identifier you want to use. Remember the discussion about openid.claimed_id? You should know by now that the value will be
http://specs.openid.net/auth/2.0/identifier_select. Here is a part of the authentication request:
Next, because realm was used, you will be asked to trust the authentication request:
Assuming you trusted the request, the response is sent back to the relying party. Here is part of the response with the signature to be verified by the application:
Finally, the application first performs another discovery on the Claimed Identifier (which is the identifier selected by the user during login), that is why you will see another XRDS document in the traffic:
Where does the attribute exchange protocol fits in this scenario? When Google authenticated me it sent back an automatically generated unique identifier:
It’s the attribute exchange protocol that allowed Google to send back my email address to the relying party.
If you examine the code in the VS 2012 project you just created, you will see that the namespace used is DotNetOpenAuth.AspNet. This is Microsoft’s wrapper around the original DotNetOpenAuth API.
Resources





can you please share the code you used here? i use mvc4/razor and integrating openid with existing application. Please Post the code with tables you use here.
i did not preserve the code. but there is nothing really special about it. the focus of the post is the protocol itself rather than .NET implementation.
if you follow the post, you'll see that i just created a VS 2012 asp.net project and uncommented the code generated by default by the template…just do the same.
hope this helps.